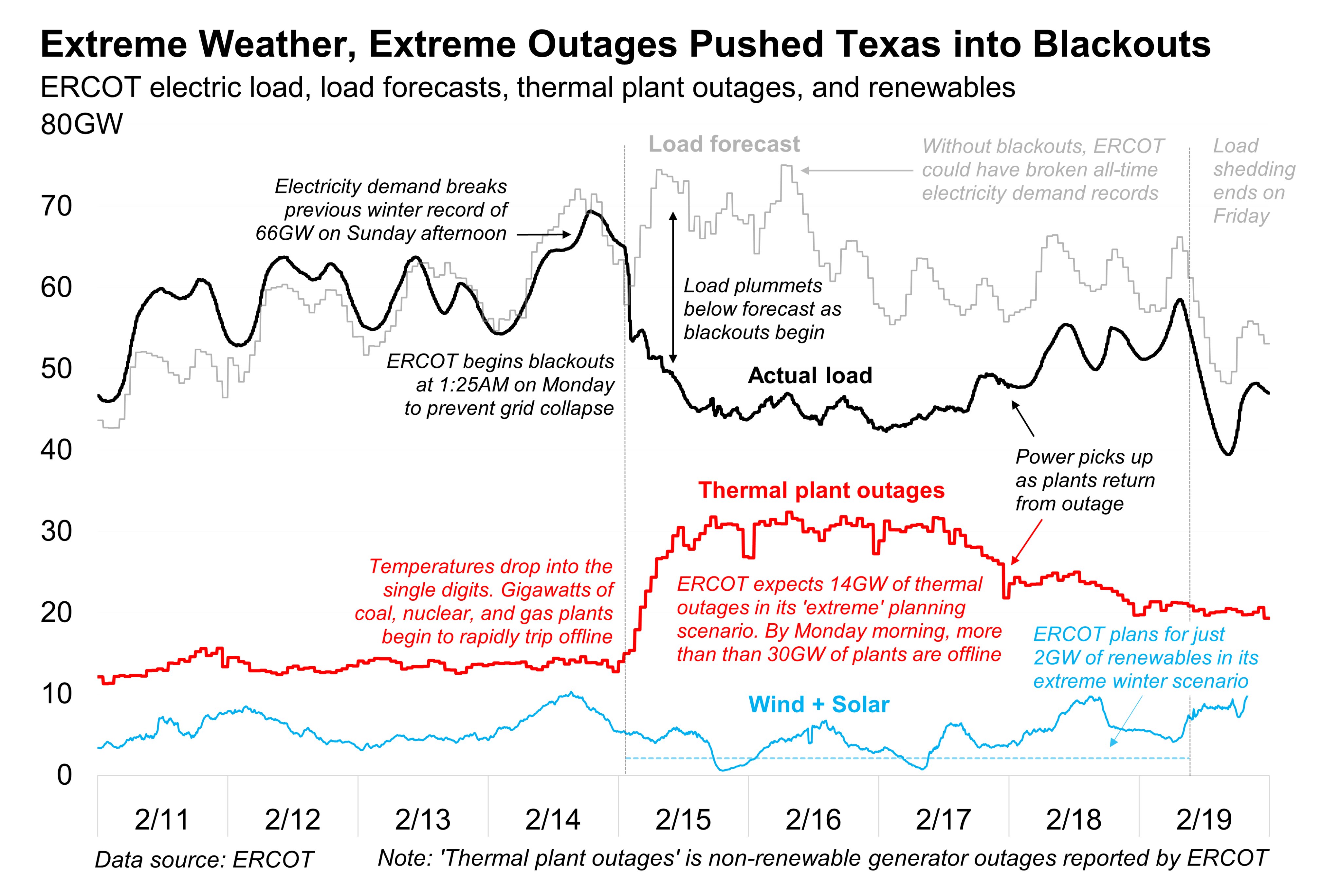
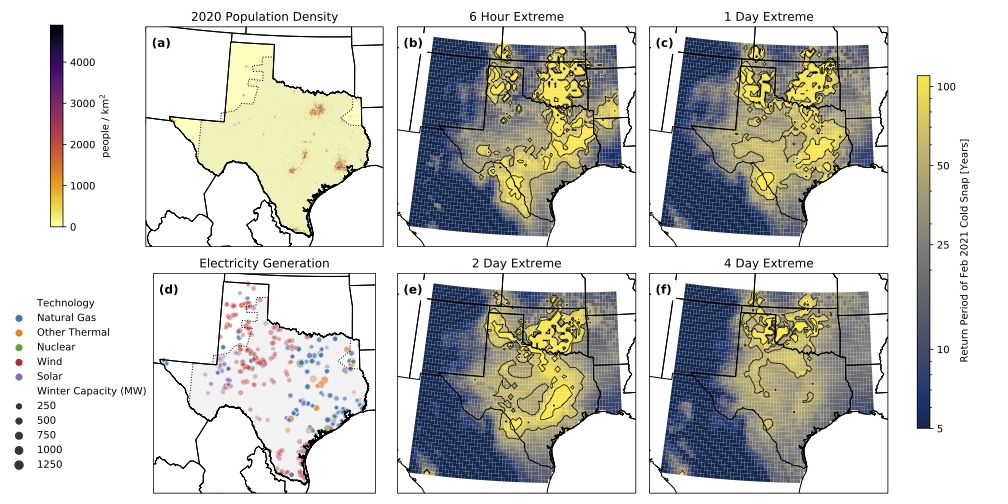
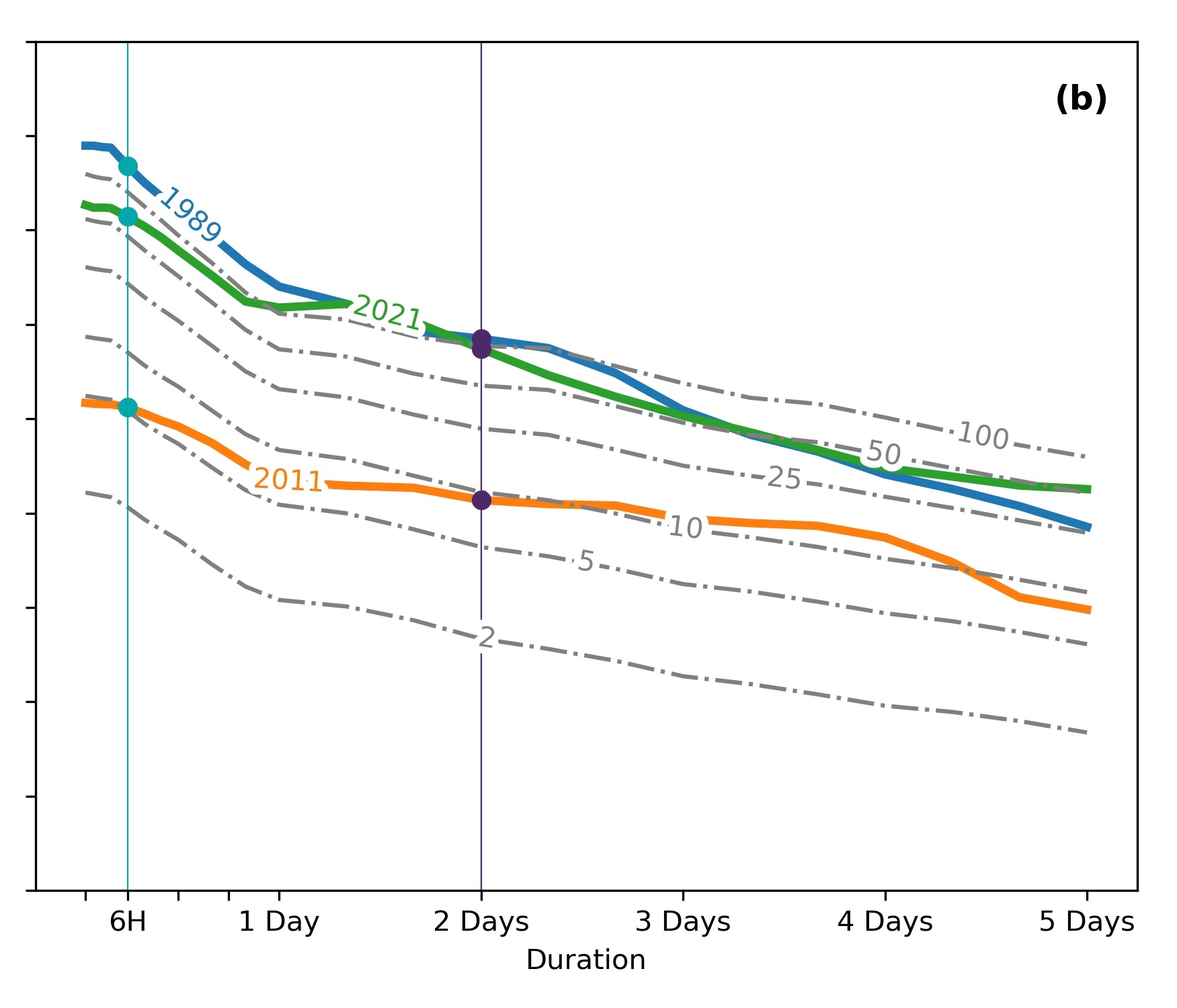
let
fig = Figure(size=(800, 400))
# Define distributions with different tail behavior
# Match location/scale to make comparison "fair"
xmin = 1.0
# Pareto distributions with different tail indices (alpha)
# α ≥ 2: finite mean and variance (physically plausible)
# α ∈ [1, 2): finite mean, infinite variance (some extreme events)
# α < 1: infinite mean and variance (very extreme, unlikely in nature)
pareto_α2 = Pareto(2.0, xmin) # α = 2: physically plausible
pareto_α15 = Pareto(1.5, xmin) # α = 1.5: very heavy tail
pareto_α08 = Pareto(0.8, xmin) # α = 0.8: infinite mean/variance
# LogNormal for comparison (light-tailed relative to Pareto)
lognormal = LogNormal(log(3), 0.8)
# Left panel: PDFs
ax1 = Axis(fig[1, 1], xlabel=L"x", ylabel=L"p(x)",
title="Probability Density Functions")
x = range(xmin, 10, length=1_000)
lines!(ax1, x, pdf.(lognormal, x), label=L"$\text{LogNormal}$", linewidth=2, color=:blue)
lines!(ax1, x, pdf.(pareto_α2, x), label=L"Pareto($\alpha=2$)",
linewidth=2, linestyle=:dash, color=:orange)
lines!(ax1, x, pdf.(pareto_α15, x), label=L"Pareto($\alpha=1.5$)",
linewidth=2, linestyle=:dot, color=:red)
axislegend(ax1, position=:rt)
# Right panel: Log-scale to see tails
ax2 = Axis(fig[1, 2], xlabel=L"x", ylabel=L"\log(p(x))",
title="Tails on Log Scale")
x2 = range(5, 50, length=500)
lines!(ax2, x2, logpdf.(lognormal, x2), label=L"$\text{LogNormal}$",
linewidth=2, color=:blue)
lines!(ax2, x2, logpdf.(pareto_α2, x2), label=L"Pareto($\alpha=2$)",
linewidth=2, linestyle=:dash, color=:orange)
lines!(ax2, x2, logpdf.(pareto_α15, x2), label=L"Pareto($\alpha=1.5$)",
linewidth=2, linestyle=:dot, color=:red)
lines!(ax2, x2, logpdf.(pareto_α08, x2), label=L"Pareto($\alpha=0.8$)",
linewidth=2, linestyle=:dashdot, color=:purple)
axislegend(ax2, position=:rt)
fig
end